
The development of AI skills (and generative AI, as part of that) is likely to have a major impact in the employability and professional success of early career graduates, both directly (i.e., in the form of demonstrated ability to use these tools) and indirectly (e.g., through impact on productivity).
As such, I am developing an AI literacy session, to be delivered as part of a series on applications of generative AI in social sciences research. The session will take place online, and the key aims are to give participants a general overview of AI and to lay the ground for the rest of the training series.
As per my usual approach, the session will follow a “Why => What => How” structure, and these are my thought so far.
Part 1: The Why
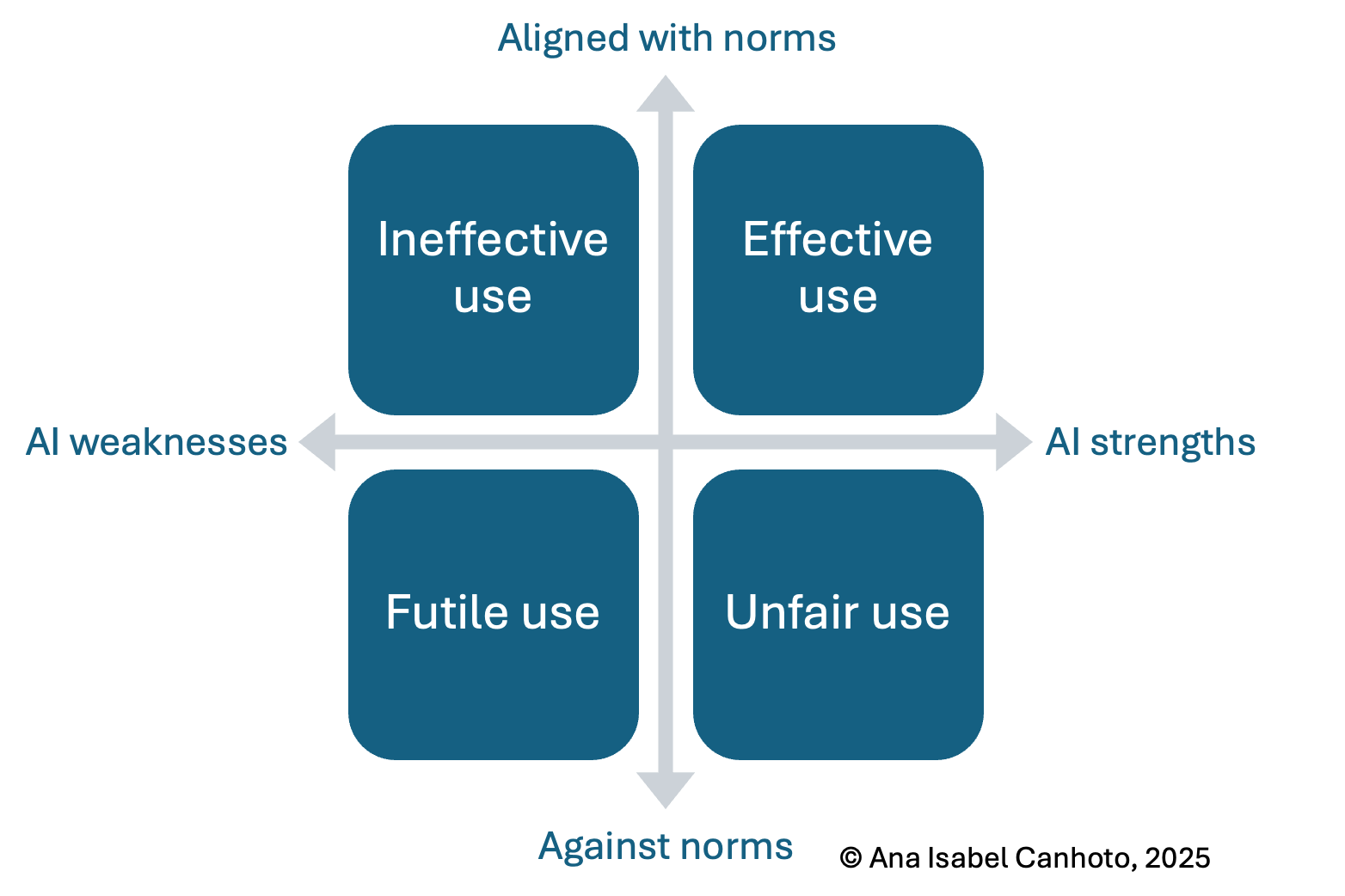
- The decision of when and how to use AI requires that we understand what this technology is good vs weak at.
- However, technology exists within a social context (read about the TFI framework, here). Thus, it is equally important that we understand the relevant norms for the use of AI in academia.
- I bring these two dimensions together to help us understand the consequences of using AI in research. We want to make sure that we are in the top right-hand corner.
Part 2: The What
- AI capabilities:
- AI as a system (data, algorithms and output), and the need for fit between characteristics of each part (e.g., type of algorithm) and the task at hand
- Different types of AI – e.g., Predictive vs Generative AI
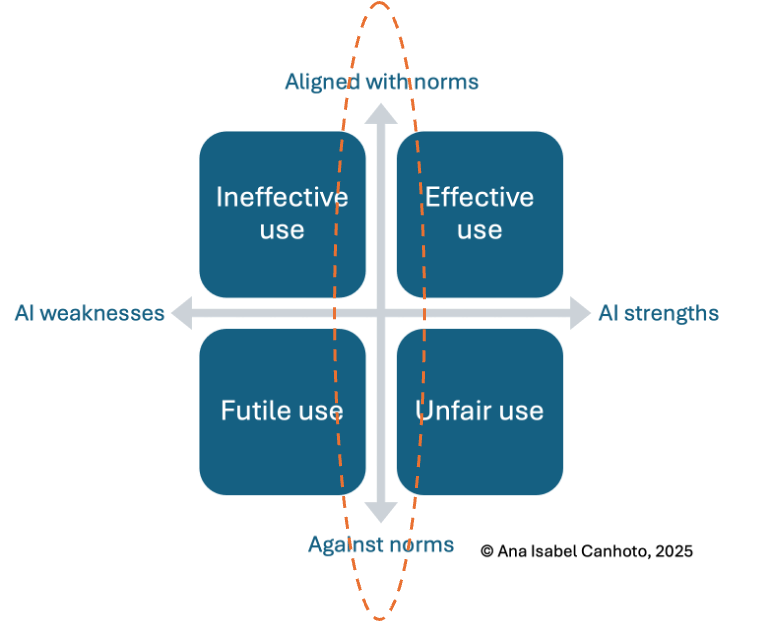
- Exercise to understand strengths and weaknesses of generative AI (horizontal axis in guiding framework)

- Research integrity:
- Formal norms – e.g., Ethical codes, data protection and journals’ guidelines
- Informal norms – e.g., Personal values (environmental cost, labour exploitation, etc…) and Normative expectations (e.g., what is expected from researchers)
- Exercise to identify relevant formal and informal norms regarding legitimate use of AI in research (vertical axis in guiding framework)
[BREAK]
Part 3: How
- Exercise to identify where use of generative AI in research may be effective vs. ineffective vs. unfair vs. futile (some examples here)
- Main generative AI chatbots and their key strengths and weaknesses, building on Ethan Mollicks’ analysis
- Examples of research-relevant products with AI-embedded (e.g., researchrabbit.ai and Napkin.ai)
- General principles to derive value from the use of generative in research, including:
- AI as a tool vs an interlocutor (as per Carrigan’s discussion on “Generative AI for Academics”)
- Value of experimentation
- Importance of research and task expertise
- Reflexivity
This is my plan so far. I would love to hear your suggestions for what is missing, what can be removed or shortened, as well as interesting examples or exercises that you may have come across.
And, please, do reach out, if you would like me to deliver AI literacy training for your group or organisation.


2 thoughts on “Outline for my AI literacy training session, for early career researchers”