

According to a market study by advisory firm Dresner, reported in Forbes, marketing managers are more likely than any other organisational function to see machine learning as critically important for the achievement of their goals. As shown in the graph below, 40% think that machine learning is critically important, and nearly two-thirds (65%) think that it is critically or very important.

I don’t know whether this perception corresponds to machine learning’s actual importance for marketing. After all, there is a difference between personalisation (for which machine learning may be essential) and being personal (which may benefit from machine learning)… and if you had to choose between the two, I would go with the latter. Having said that, I believe that every marketer and every marketing student need to, at least, know what machine learning is, and how it can be used in marketing, so that they can make informed decisions about it. So, here is a brief introduction, and a simple crib sheet, to demystify the term.
First things first. Machine learning is one particular type of algorithm. An algorithm is a particular way of putting data together to achieve a certain goal, like a recipe is a particular way of putting ingredients (say, eggs, flour, sugar and milk) together to make a cake vs a pancake vs a soufflé.
The particular way of putting the data together – i.e., the algorithm – can be dictated by a programmer, as in the case of a rule-based system. Think of rule-based systems as using a familiar recipe to mix those eggs, flour, sugar and milk to make a delicious cake. Alternatively, the way of arranging the data can be learned by the computer. That is the case of machine learning. Think of machine learning as recipe development by trying different ways of combing the eggs, flour, sugar and milk to make a delicious cake.
Hence, a crude description of a machine learning algorithm could be that it is a computer programme that uses observations about patterns in a dataset to develop rules that it, then, applies to other datasets, adaptively. While not all Artificial Intelligence solutions use machine learning algorithms, machine learning is the type of algorithm that underpins many customer facing applications such as movie recommending systems, or chatbots. So, let’s focus on this type of algorithm for the time being.

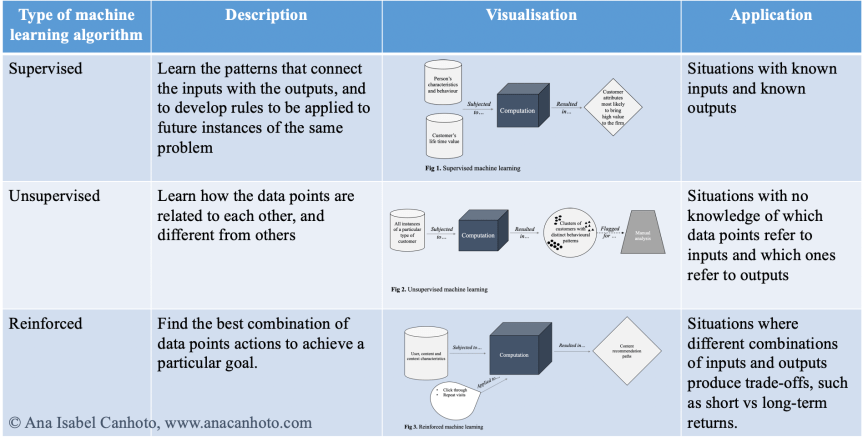
There are different types of machine learning algorithm, each applicable to a different type of problem.
One type of machine learning is supervised machine learning where (human) experts give the computer training datasets with both the inputs and the correct outputs. The function of the algorithm is to learn the patterns that connect the inputs with the outputs, and to develop rules to be applied to future instances of the same problem. For instance, we could use a database of past customer transactions and characteristics (inputs), plus one of different customers’ life time value for the organisation (the outcome), so that the algorithm can be trained to detect variations in customer characteristics and behaviour, and find the ones most likely to bring high value to the firm, overtime.

The opposite approach is unsupervised machine learning where the computer is given a training dataset with no labels. The algorithm’s task is to find the best way of grouping the data points, and develop rules for how they may be related. For instance, we could give the computer a dataset with the transaction patterns of a particular type of customer (e.g., customers in the target market). The algorithm sorts through the transaction patterns and identifies clusters within that group with distinct behavioural patterns – say, how they buy, what they buy, etc. Marketers can, then, use this information to decide on appropriate marketing strategies (e.g., store location, mix of products…) to reach the targeted customers.

An intermediary approach is reinforced machine learning. The computer is given a dataset plus a goal, and is left to find the best combination of actions to achieve that goal. To do that, we also need to give the computer rewards (or penalties) for the actions that it takes. For instance, in a content recommendation system, we could give the computer a dataset about customers, about types of content, and about the context (time of the day, day of the week, previous websites visited…), as well as the goal to maximise long-term viewer retention. The rewards could be a mix of measures such as clicks on news’ headlines and repeat visits to the website. The algorithm would sort through possible combinations of content delivery and analyse the rewards (clicks and repeat visits), to decide which recommendation paths to follow (i.e., what content is delivered in what sequence), to each customer, in different contexts, in order to maximise the goal of long-term viewer retention.

The choice of machine learning algorithm should be based on fit with type of problem. Supervised machine learning is indicated for situations with known inputs and known outputs. Unsurprised machine learning is indicated for datasets where it is not known which data points refer to inputs and which ones refer to outputs. Reinforced machine learning is particularly useful for problems where different combinations of inputs and outputs produce trade-offs, such as short vs long-term returns.
And, now, here is the promised crib-sheet.
Let me know what you think of this description and crib sheet. Additional examples, and suggestions would be most welcome!


11 thoughts on “Types of machine learning – a crib sheet for marketers”