
While I warmly encourage everyone to get familiar with generative AI, I often suggest that they use it mostly for purposes where it doesn’t matter if the answer is correct or not. If one must use it in a context where accuracy matters, then I suggest using it only when we know the answer and can check if it is correct.
That’s because generative AI doesn’t really care about true vs false – only about common vs not common. Here is an example from a recent conversation with Chat GPT:
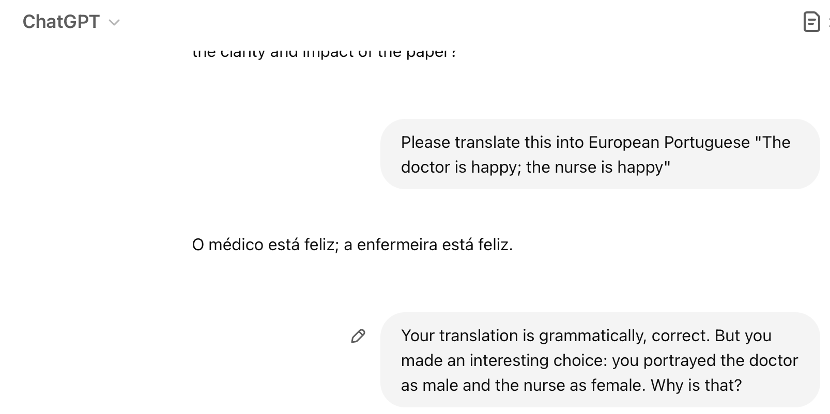


My concern in this exchange wasn’t even inclusivity. It was mostly the inaccuracy of the output and the clear lack of concern about giving the user the right answer. Because, you know, algorithmic biases are not unavoidable. As explained in the fantastic paper “Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings” co-authored by Tolga Bolukbasi, Kai-Wei Chang, James Zou, Venkatesh Saligrama and Adam Kalai, it is actually possible to debias algorithms.

Ian McCarthy, Timothy R. Hannigan and André Spicer provide a great framework for deciding whether and how to use generative AI chatbots in order to avoid this very same problem. In the meantime, if you feel tempted to ask a generative AI chatbot to define concept X, explain how to do Y or, you know, translate Z, take a step back and ask yourself: Do I need an accurate answer? If the answer is yes, and you are not an expert on the topic, use another tool.


Fantastic post! Though, if I may add in my two cents — just an observation on the chatbot’s use of gendered language. I guess it’s also stems from the materials used to train the LLM?
I noticed that the concept of -o and -a is common in both Lusophone and Hispanophone materials (and this particular rule extends to nations under Spain and Portugal). With the wide array of materials used to train ChatGPT, those materials that make use of these linguistic rules may not have been updated in time (given the Herculean task required of it).
LikeLike
Agree.
What I found interesting was the justification: the LLM “knew” that the answer wasn’t following linguistic rules. It was a choice to go with the popular answer, rather than the linguistically correct one.
LikeLiked by 1 person