
There is a lot of enthusiasm about the potential of artificial intelligence in general, and machine learning in particular, to solve just about any problem on Earth. Thus, a special issue of the Journal of Business Research is looking at the potential of those technologies to meet the United Nations 17 Sustainable Development Goals; and that includes one paper authored by me.
The Sustainable Development Goals (or SDGs, for short) are a global agenda for sustainable development, set out by the United Nations General Assembly, in 2015. Each individual goal is concerned with a particular social, economic or environmental issue, ranging from poverty elimination (Goal 1) to the strengthening of global partnerships (Goal 17). Together, the goals constitute an ambitious development agenda, which will require the concerted efforts of governments and private institutions across the world, and across all goals, in the period leading up to the year 2030.
One of those goals – Goal 16 – focuses on crime reduction. What does crime have to do with economic development? Well, as it turns out, quite a lot!
It has been shown that economic development is negatively correlated with crime. Moreover, crime reduction results in more stable societies, enhances effective governance and promotes citizens’ well-being – all, of which, are markers of sustainable economic development, as defined by the UN.
Because money is both a key motivator and a key enabler of criminal activities, many governments and international institutions see the ability to curtail the movement of money to and from criminal organisations as a key tool in fighting crime. This is done through programmes of anti-money laundering and terrorism financing initiatives, or AML programmes for short. Technology plays a key role in those programmes, because all financial transactions (other than direct cash payments) leave electronic traces, which can be processed and analysed in order to develop insight about the financial behaviours of criminals, and to limit their access to cash.
In recent years, there has been a growing interest in exploring the potential of artificial intelligence and machine learning to support AML programmes and, thus, the global fight against crime. Advocates highlight machine learning’s ability to handle large volumes of data, both structured and unstructured, and its potential to discover the patterns of financial behaviour adopted by those engaging in illicit activity (e.g. here). However, the industry remains cautious, and the use of these technologies is, so far, more experimental than systematic (e.g., here).
In order to reconcile these two opposing views regarding the potential of machine learning technology for crime reduction, via its inclusion in AML programmes, I have looked at the extent to which machine learning algorithms can be leveraged to assist with the detection and prevention of money laundering and terrorism financing in the UK. My analysis is reported in the paper entitled “Leveraging machine learning in the global fight against money laundering and terrorism financing: An affordances perspective” that has just been published in the Journal of Business Research.
The suitability of machine learning for AML
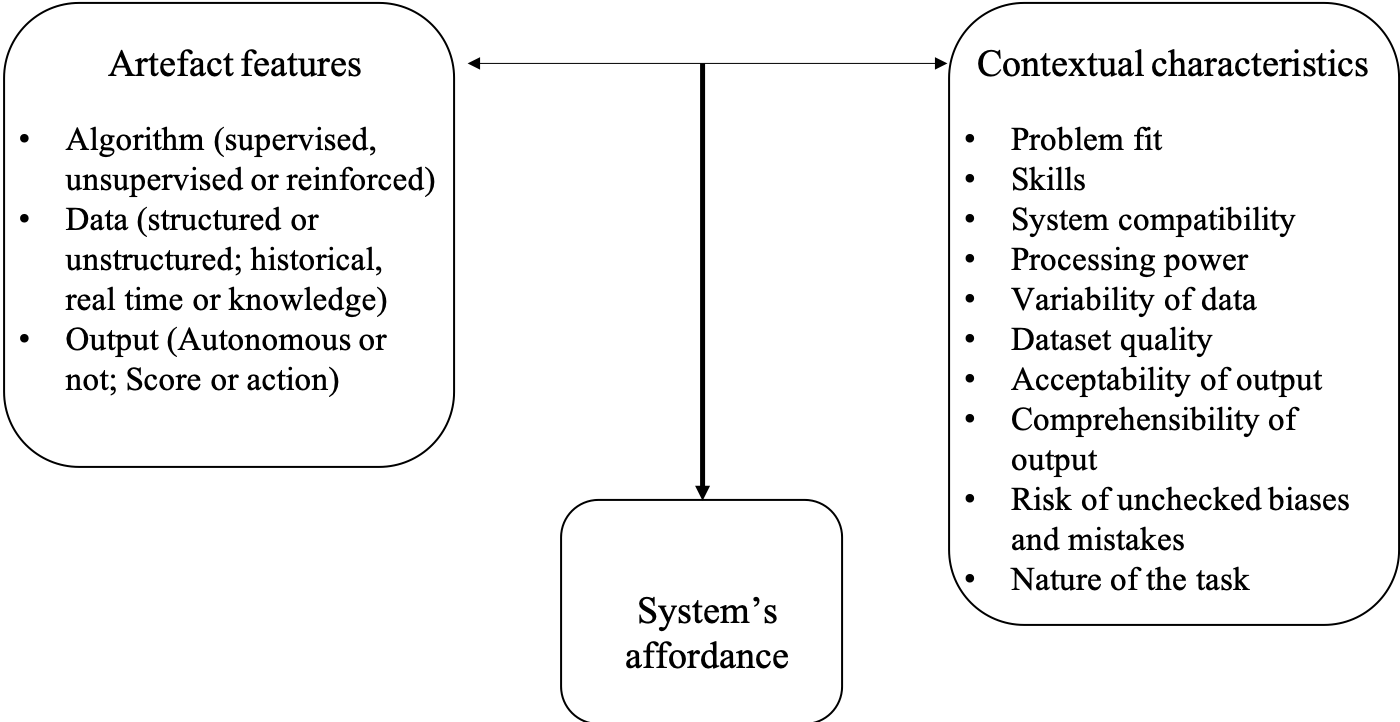
Defendants of machine learning use in AML highlight the potential of this technology to discover novel patterns in financial transaction data, and to do so in a cost-effective manner. However, whether that potential is realised or not depends entirely on the interplay between the technical and contextual features of AML programmes.
There are various types of machine learning, each applicable to a different type of problem. Supervised machine learning is indicated for situations whereby there are known inputs and known outputs; unsupervised machine learning is indicated for data sets where it is not known which data points refer to inputs and which ones refer to outputs; and reinforced machine learning is indicated for problems where certain courses of actions produce better results than others. The potential of machine learning to be used in different scenarios is shaped by technical features such as its ability to learn patterns in data, process various types of data and act autonomously. Moreover, it is shaped by contextual features such as the type of problem to which it is applied, the analyst’s skills, system compatibility, processing power, variability of data, quality of the data set, acceptability of the output, comprehensibility, risk of unchecked biases and mistakes and the nature of the task.
Findings
Based on my analysis of what money laundering is, the type of data accessible to financial institutions in the UK, and the state of technology, I conclude that there are some opportunities for using machine learning to assist with identifying unusual transaction patterns, or even with suspicious behaviour more generally, but not money laundering per se.

On the one hand, this is because of the nature of the phenomenon being modelled. Namely, money laundering is a multi-dimensional phenomenon, characterised by secretive and deceptive behaviours, and which is constantly evolving. On the other hand, this is because of the specific position of financial services organisations in the money laundering supply chain, the limited perspective that they have on their customers’ transactions and the nature of the AML task that they are asked to perform (i.e. prevent money laundering).
While financial services organisations may be essential enablers of money laundering and, indirectly, criminal activity, their perspective is limited to the transaction data for their own customers and their own institution. Money laundering often involves multiple individuals and institutions, possibly in multiple jurisdictions, and may take place over an extended period of time. In particular, the type of transnational, organised crime mentioned in the U.N.’s SDG 16 may be difficult to detect via routine AML monitoring by any individual financial services organisation. In some jurisdictions, such as Italy, AML monitoring is done at the national level, rather than at the organisational level as is the case of the UK. It is possible that machine learning would be effective for AML at the national level, for either descriptive or predictive profiling, but not in the current setting.
Moreover, it is true that financial services providers hold a large volume of data about their customers’ identity and behaviour. However, they lack timely, relevant and sufficient data about money laundering behaviours with which to train machine learning algorithms. As is the case with the novel SARS-CoV-2 virus, the key to unlocking the processing power of machine learning is the training dataset. Without such datasets, the actual value of this technology falls very much short of its potential, yet this aspect is largely absent from the discussion about the application of machine learning in AML, or, indeed, other areas.
My paper also emphasises the influence of analysts throughout the whole process of data collection and analysis, questioning claims that using technology can eliminate human bias in AML. Furthermore, my paper identifies a range of individual, organisational and societal costs arising from classification errors, and argues that such costs need to be taken into consideration when assessing the value of using machine learning not just in AML, but other contexts.
You can access my paper here. An open access version is available here.


7 thoughts on “New paper: Leveraging machine learning in the global fight against money laundering and terrorism financing: An affordances perspective”