
There are numerous examples of how the datasets that are used to train the algorithms that rule our daily lives are biased. For instance, tools that automatically translate professional titles tends to follow gender stereotypes: males are doctors while nurses are females. There is also bias against faces of females and faces of people of colour.
But if these biases are so widely known, and so problematic, why do they persist?
According to a study by Bernard Koch, Emily Denton, Alex Hanna and Jacob G. Foster, the problem persists because the same small number of training datasets are used over and over and over again. In the paper “Reduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research”*, published in the arXiv repository, the authors share the results of their study.
Datasets are “the backbone of machine learning” (ML) (page 1) because, before they are deployed, ML algorithms are trained and tested on existing datasets. In particular, they are tested against benchmark datasets, which are deemed to hold “meaningful abstractions of a task or problem domain” (page 1). Improving the score of an algorithm against the relevant benchmark dataset is supposed to mean that the algorithm is getting better.
The authors also note that dataset development is time- and labour-intensive, and requires access to “unique or privileged data (e.g., anonymized medical records, self-driving car logs)” (page 8), making “large-scale dataset development potentially inaccessible to lower-resourced institutions” (page 3).
Because of the high cost and lack of incentives to develop new datasets on the one hand, and the role of established benchmark datasets in training and signalling the quality of ML algorithms on the other, Koch and the team set out to study:
- The extent to which research within task communities** is concentrated or distributed across different benchmark datasets;
- Patterns of dataset creation and adoption between different task communities; and
- The institutional origins of the most dominant datasets.
In relation to question 1, the team found that there was significant evidence of increasing concentration in fewer and fewer datasets, across various task communities included in this study. This is illustrated in Figure 1:

In relation to question 2, the authors found that the various task communities were creating new datasets (bottom of figure 2). However, “the newly created datasets are being used at lower rates” than the pre-existing datasets that had been developed for a different a task (page 8). Namely, “in more than half of Computer Vision communities, authors adopt at least 71.9% of their datasets from a different task” (page 6); though, the equivalent statistic for Natural Language Processing communities is 27.4%.

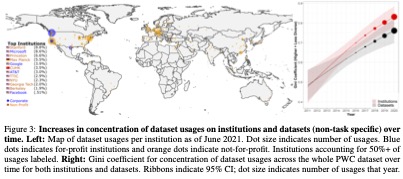
And last but definitely not least, in relation to question 3, the research team found that “widely-used datasets are introduced by only a handful of elite institutions (Figure 3 left). In fact, over 50% of dataset usages in PWC as of June 2021 can be attributed to just twelve institutions. Moreover, this concentration on elite institutions as measured through Gini has increased to over 0.80 in recent years (Figure 3 right red). This trend is also observed in Gini concentration on datasets in PWC more generally (Figure 3 right black).”
Why is the concentration on a small number of benchmark datasets, and their re-use in tasks different from the one they were created for, a problem?
Using benchmark datasets out of context give unreliable measures of performance, which create the problems of bias that we are all familiar with. When the algorithms trained with those datasets are applied in decision making (e.g., CV screening), they propagate the gender and racial biases present in those datasets, and adversely affect the groups under-represented in the datasets (or the opposite, in the case of policing datasets).
But another – and more – subtle dynamic occurs: The continued reuse of a small number of datasets artificially increases their perceived value for each task community. This reinforces the concentration of resources (time, money and privileged datasets) in a small number of institutions and, therefore, perpetuates the problem of lack of diversity and representation in benchmark datasets. A catch 22!
*Great title!
**task communities are the ML programming communities focused on specific algorithmic tasks such as sentiment analysis or face recognition


One thought on “The handful of datasets that rule our lives”