
Emotions are key to explain and anticipate consumer behaviour, and sentiment analysis offers marketers a way of measuring and summarising those emotions. Emotions displayed on social media conversations, in particular, are very appealing for research, as these platforms offer many opportunities to listen to the conversations in real time, with minimum disruption for the individuals expressing those emotions and in a cost-effective way.
Despite its promise and popularity, the sentiment analysis of social media conversations is neither a simple nor a straightforward process. Yuvraj Padmanabhan and I investigated the vulnerabilities present in processing and analysing Twitter data concerning consumers’ sentiment towards coffee. Our study, which has just been published in the Journal of Marketing Management, showed low levels of agreement between manual and automated analysis:
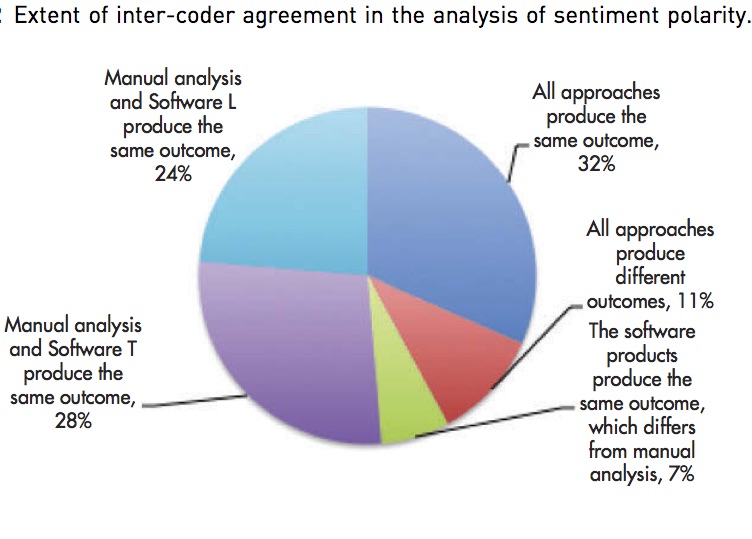
Source: Canhoto and Padmanabhan (2015)
Why?
Focusing on those messages where all types of coders agreed, it is interesting to see that they are most likely to reflect positive emotions, as exemplified by these tweets: ‘Found a euro cent on my walk and have a great cup of coffee in hand. Monday is already off to a good start’ and ‘Feeling much more alive this morning now that I’ve had my coffee’. Similarly, emotions that were clearly positive, like ‘joy’, showed higher rates of inter-coder agreement than those that showed passive emotions.
Conversely, problems arose when:
- A negative sentiment was expressed but this resulted from the absence of coffee;
- A sentiment was expressed but this referred to a different object (e.g. shift work), not the coffee;
- The sentiment was not explicitly expressed but rather implied through cultural associations such as having coffee out, or through emoticons or abbreviations;
- The user employed irony or sarcasm.
There were also cases where the sentence contained the word coffee and expressed a sentiment, but did not refer to the drink itself and, thus, should be excluded from the corpus of analysis.
In our study, not only were multiple types of software used, but also software products from both a commercial and an academic origin were employed. There were no marked differences in performance between the various products, indicating that this is not a failure of one product or the other but, rather, a challenge presented by the subject matter (emotions and sentiments) and by the channel, with its technical limitations and very specific culture and netiquette. These challenges are accentuated by the fact that the segments of text available on Twitter are very short, rich in abbreviations and slang, and often with typos or grammatical errors.

Source: Canhoto and Padmanabhan (2015)
So what?
These vulnerabilities have a number of effects on the use of automated tools to analyse sentiment in online conversations.
The first effect is that the problems with classification of tweets lead to an inaccurate representation of the overall sentiment towards coffee, both in terms of sentiment polarity and in terms of emotional state. The second effect is that segments of text that should be excluded from the analysis because they do not relate to the topic under analysis – coffee – are retained in the corpus of data, possible skewing the results. Given that so many commercial and academic research projects rely on the automated analysis of sentiment data, these findings raise concerns for the quality of those insights and subsequent decisions.
One of the reasons why using qualitative data analysis software may improve the credibility of a qualitative study is that the software enables researchers to make visible their data coding and data analysis processes. This is not the case with most automated sentiment analysis tools, given that the coding and analysis process is performed by algorithms strongly guarded by the commercial organisations that sell these applications. It is also concerning because researchers in search of speedy and inexpensive customer insight are unlikely to assess the robustness of the automated tools prior to using them, as we did in this study.
What can we do about it?
Our study does not aim to discourage researchers from using automated sentiment analysis tools, or Twitter data. Instead, our message is that researchers need to spend considerable time familiarising themselves with the technical and pragmatic aspects of communication in the social environment, and with the characteristics and limitations of the software that they may use to analyse social media data. To improve the classification of tweets, sentiment analysis needs to take into consideration the social context within which the conversation takes place, for instance by looking at the tweets before or after the one being coded, or considering wider patterns (e.g. more negative tweets on Mondays). Moreover, analysts need to consider the cultural connotations of the object that they are studying, including international variations – for instance, in Japan the consumption of coffee is associated with the idea of foreignness, whereas this is no longer the case in the United Kingdom. Additionally, it is important to keep developing dictionaries that reflect the specific syntax and style used in social media conversations, or even software solutions that, in the first stage of analysis, replace commonly used abbreviations with their formal equivalent – for instance, replacing BRB with ‘be right back’. However, it must be recognised that as language and communication styles are constantly evolving, these dictionaries and tools will never completely reflect the full variations and nuances in social media communication. Moreover, they will struggle to capture sarcasm and highly contextualised uses of language – for instance, teenagers using the term ‘sick’ to refer to a very good experience.
You can access our paper here.
What challenges have you faced when using Twitter data to study sentiment, and how do you deal with them?


13 thoughts on “Studying sentiment on Twitter is… complicated”